A Return on Intelligence Analysis for Technical Leaders
In January 2026, Alibaba’s Qwen quietly crossed 700 million cumulative downloads quietly overtaking Meta’s Llama to become the world’s most-downloaded open AI model family. The Qwen3 architecture alone (spanning 0.6B to 235B-A22B MoE configurations) now generates more monthly downloads than OpenAI, Mistral, NVIDIA, Zhipu, Moonshot, and MiniMax combined.
Beneath the surface metrics lies a more significant technical story. The Hugging Face ecosystem now hosting 2.4 million models with 145 million monthly hub downloads and 3.6 million daily transformers library installs offers empirical signal on which architectural patterns are gaining production traction versus which remain benchmarking artifacts.
This analysis maps download statistics to architectural decisions: what the data reveals about model sizing, inference optimization, reasoning patterns, and the emerging case for hybrid architectures that combine deterministic and probabilistic components.
Signal 1: The Parameter Efficiency Inflection
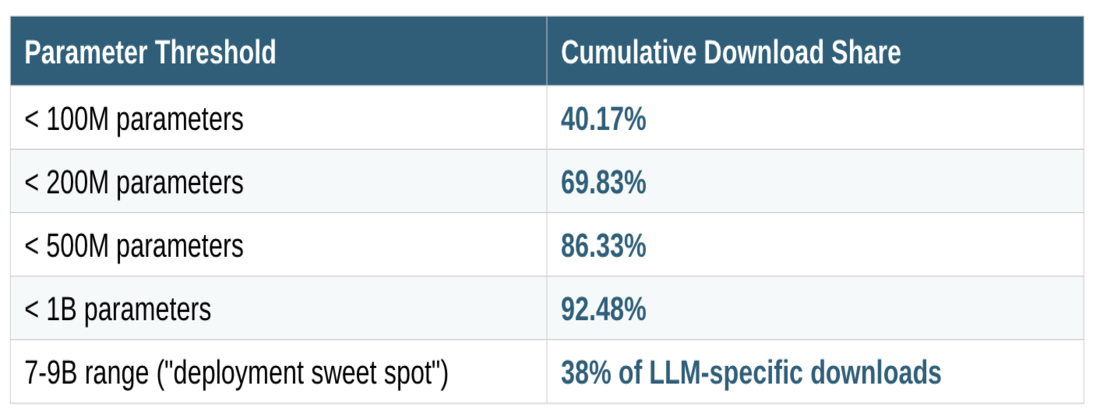
Analysis of the top 50 downloaded entities (representing 80.22% of all Hub traffic, or 36.45B of 45.44B total downloads) reveals a striking distribution: 92.5% of downloads concentrate in models under 1 billion parameters. The breakdown is instructive:
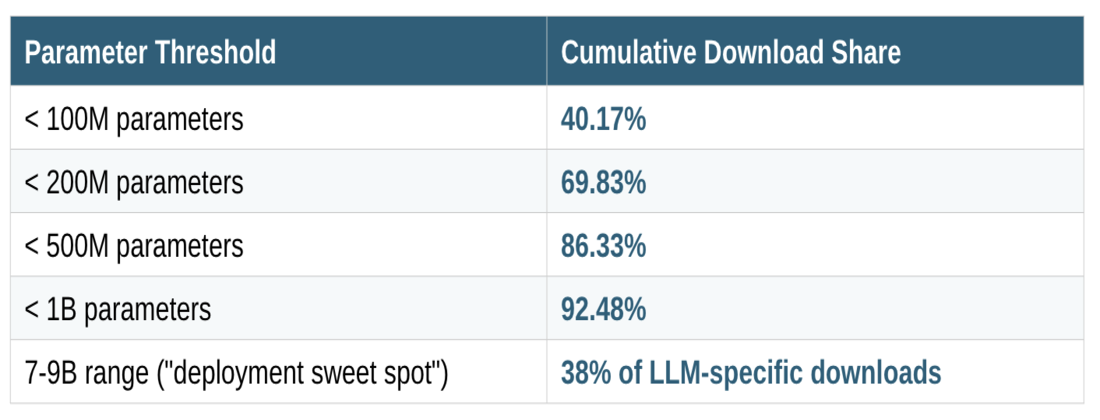
The 7-9B sweet spot reflects a hardware-software co-optimization: these models fit comfortably in single-GPU VRAM (24GB consumer, 48GB professional) with INT4/INT8 quantization while maintaining acceptable quality degradation. Quantization format preferences in the download data reveal deployment priorities GGUF dominates for CPU/Apple Silicon inference (llama.cpp, Ollama ecosystems), AWQ leads for quality retention at 4-bit, and GPTQ with Marlin kernels achieves highest throughput (712 tok/s vs 461 baseline on benchmarks).
Technical Implication: The market is optimizing for inference economics over benchmark scores. When evaluating model selection, the relevant metric isn’t MMLU or HumanEval it’s quality-adjusted cost per million tokens at your target latency percentile. The concentration in sub-1B models (primarily encoders and embedding models) suggests most production AI workloads don’t require generative capabilities at all.
Signal 2: The MoE Architecture Ascendancy
September 2025 marked a geographic inflection: Chinese-originated models surpassed US models in new Hugging Face downloads. But the more significant technical story is architectural. The three models driving this shift; DeepSeek R1/V3, Qwen3, and Kimi K2 share a common pattern: Mixture of Experts (MoE) architectures that decouple total parameters from inference-time compute.
The derivative model metric proves most revealing. By September 2025, 63% of all new fine-tuned models uploaded to Hugging Face were based on Chinese base architectures. Meta Llama’s derivative share collapsed from ~50% (fall 2024) to 15% (end 2025). At the 250B+ parameter tier, DeepSeek captures 56% of downloads versus Qwen’s 1% indicating DeepSeek’s dominance in frontier reasoning workloads.
Technical Implication: MoE architectures enable a new optimization frontier massive knowledge capacity (total parameters) with bounded inference cost (active parameters). DeepSeek R1’s training cost of $5.6M versus hundreds of millions for comparable dense models demonstrates the economics. For enterprises, this means evaluating models on active parameter count for inference planning while considering total parameters for capability assessment.
Signal 3: The Reasoning-via-RL Paradigm Shift
OpenRouter, a unified API gateway routing requests across 300+ models from 60+ providers to 5+ million developers published a “State of AI 2025” analysis covering 100+ trillion tokens processed between November 2024 and November 2025. This dataset represents actual inference workloads (not downloads), offering a complementary lens on production usage patterns.
Important context: OpenRouter’s user base skews toward developers and API-first applications it’s not representative of enterprise chatbot deployments or consumer-facing products. However, for understanding how technical practitioners are actually using models (versus downloading them), this is the most granular public dataset available.
The data documents a phase transition: reasoning models grew from negligible usage to over 50% of all tokens processed by late 2025. The inflection point was DeepSeek R1’s January 2025 release, which demonstrated that sophisticated reasoning could emerge through pure reinforcement learning without supervised fine-tuning.
DeepSeek-R1-Zero, the RL-only variant exhibited emergent behaviors previously assumed to require human-curated reasoning traces: self-verification, reflection, and extended chain-of-thought. This validated a training paradigm where reasoning capabilities emerge from reward signal alone, reducing dependence on expensive human annotation.
The distillation patterns in download data reveal how this propagates: DeepSeek-R1-Distill-Qwen-32B leads at 2.54 million downloads, outperforming OpenAI o1-mini on several benchmarks while running on consumer hardware. Six distilled variants (1.5B-70B) based on Llama and Qwen backbones demonstrate the transferability of reasoning capabilities across architectures.
Concurrent with reasoning growth, programming tasks expanded from 11% to over 50% of token volume. Qwen3-Coder-480B-A35B achieves 69.6% on SWE-Bench Verified indicating convergence between reasoning and code generation workloads.
Token volume by model provider (OpenRouter, Nov 2024-Nov 2025): DeepSeek led open models at 14.37 trillion tokens, followed by Qwen (5.59T), Meta Llama (3.96T), and Mistral (2.92T). For comparison, closed-model leaders included Grok Code Fast 1 (16.06T), Claude Sonnet 4 (9.77T), and Gemini 2.0 Flash (9.16T). Open-source models collectively reached ~30-33% of total token volume by late 2025, up from ~15-20% a year earlier.
Technical Implication: The reasoning-via-RL paradigm changes the build-vs-buy calculus. Organizations can now distill reasoning capabilities from open models (MIT/Apache licensed) into domain-specific variants. The architectural pattern base LLM + RL-trained reasoning layer is reproducible. For compliance-sensitive domains, this enables reasoning systems where the training process is auditable and the weights are owned.
Signal 4: The Encoder/Embedding Infrastructure Layer
The modality distribution in download data challenges LLM-centric narratives: NLP models capture 58.1% of downloads, but within NLP, text encoders (BERT-style) represent 77.5% while decoder-only LLMs account for just 16.5%. This means LLMs represent only ~9.5% of total platform downloads.
The individual model leaderboard reinforces this: google-bert/bert-base-uncased leads at ~4.5 billion cumulative downloads. sentence-transformers/all-MiniLM-L6-v2 sees 146 million monthly downloads exceeding any LLM. OpenAI’s CLIP (72% of their HF downloads) and Whisper (28%) dominate their category through specialized architectures, not generative scale.

Technical Implication: Production AI systems are layered architectures where LLMs handle generation but encoders/embeddings handle the majority of compute. RAG pipelines, semantic search, classification, and similarity matching rely on the “boring” infrastructure models. Architecture decisions should allocate engineering investment proportionally the embedding layer often determines system quality more than the generation layer.
The Architectural Synthesis: Hybrid Reasoning Systems
These four signals parameter efficiency concentration, MoE architecture ascendancy, reasoning-via-RL validation, and encoder infrastructure dominance converge on a single architectural thesis: production AI systems require hybrid architectures that compose multiple model types with deterministic components.
Hybrid Architecture Pattern: Deterministic + Probabilistic
For domains where errors carry material consequences financial services, healthcare, legal, compliance pure probabilistic inference is insufficient. The architectural pattern should cover probabilisitc , deterministic and routing considerations.
Hybrid Architecture Pattern: Multi-Model Composition
The download data reveals that production systems aren’t single-model deployments. The pattern that emerges:
Embedding Models (sub-500M): High-throughput vector generation for retrieval, similarity, and classification. These handle the majority of inference volume at minimal cost.
Routing Models (1-3B): Intent classification and query routing that determines which downstream model handles each request. SmolLM-class models excel here.
Generation Models (7-9B): The “sweet spot” tier handling standard generation tasks. Qwen2.5-7B-Instruct and Llama-3.1-8B-Instruct dominate this segment.
Reasoning Models (32B+ or MoE): Invoked selectively for complex queries requiring multi-step reasoning. DeepSeek-R1-Distill variants or Qwen3-32B-A3B handle this tier.
Implementation Decision Framework
When architecting hybrid systems, technical leaders should evaluate:
1. Error Tolerance Profile: What’s the cost function of incorrect outputs? High-stakes domains require deterministic validation layers; low-stakes applications can rely more heavily on probabilistic inference with graceful degradation.
2. Reasoning Depth Distribution: Profile your query workload what percentage requires multi-step reasoning versus retrieval/classification? The 50%+ reasoning token share on OpenRouter reflects a developer-heavy, API-first user base building agentic applications; enterprise chatbot and internal tool workloads typically skew toward simpler queries with lower reasoning requirements.
3. Model Portability Requirements: The 63% derivative shift toward Chinese models happened in ~12 months. Architect abstraction layers that enable base model swaps without system redesign. Evaluate inference frameworks (vLLM, TensorRT-LLM, llama.cpp) on model coverage breadth.
4. Inference Economics: Calculate cost-per-query at target latency across model tiers. MiniMax M2 operates at 8% of Claude Sonnet’s API cost with 2× faster inference economics that compound at scale. The 92% sub-1B download concentration reflects enterprises optimizing this metric.
5. Compliance Surface Area: Identify which system components require audit trails, explainability, or regulatory approval. Hybrid architectures enable concentrating compliance investment on the deterministic layer while allowing probabilistic components to evolve independently.
The Contours of What’s Next
Download statistics are a noisy proxy they measure interest rather than deployment, HTTP requests rather than inference, popularity rather than production value. Hugging Face’s methodology counts every GET request to model storage, including CI/CD pipelines and automated tooling.
But the patterns that emerge from 45+ billion downloads across 2.4 million models offer signal that cuts through vendor marketing: the market is optimizing for efficiency over scale, MoE architectures over dense transformers, reasoning capabilities over general benchmarks, and infrastructure models over headline-grabbing LLMs.
The 700 million downloads flowing to Qwen represent a specific technical choice: permissive licensing, comprehensive model coverage (0.6B to 235B), hybrid reasoning modes, and frequent iteration. The 63% derivative share shift represents developers voting with their compute budgets.
For technical leaders, the implication is architectural: the winning systems won’t be single-model deployments. They’ll be hybrid compositions deterministic and probabilistic, small and large, specialized and general orchestrated to match model capabilities to task requirements. The download data suggests the market is already building this way. The question is whether your architecture reflects that reality.
This analysis is part of Return on Intelligence Newsletter, exploring how AI transforms enterprise architecture. All IP rights are reserved by HeliOS OpenInnovation Ventures, UK. If you wish to reuse the article please do so with an attribution aligned to Creative Commons Licensing.
Data sources: Hugging Face Hub download statistics (45B+ cumulative downloads tracked); ATOM Project (atomproject.ai) for US-China competitive analysis; Stanford HAI/DigiChina “Beyond DeepSeek” policy brief (December 2025); OpenRouter State of AI 2025 report analyzing 100T+ tokens of actual inference traffic across 300+ models. Download data measures interest/experimentation; token data measures production inference workloads.
What architectural patterns are you seeing gain traction in your deployments?